Note: This is article is part of a series. If you have not yet read the first installment, you may be missing some context. Note: Pretty much all the code reported in this and the following articles in this series is simplified or abridged in some way and may contain inaccuracies. Readers interested in the end-result may find it at the following GitHub repo: https://github.com/gooplancton/irc-server-rust
In the last part, we have leveraged the power of procedural macros to allow us to specify the type of the payload of any command in the IRC wire protocol and parse it from the open TCP socket with the client. In this article we are going to implement most of the networking code required to make our application work. Along the way, we’re going to learn about TCP sockets, threads and synchronization primitives in Rust.
Part 2: Blocking Server
Here’s what our server code looks like so far:
fn main() {
let listener = TcpListener::bind("127.0.0.1:6667").unwrap();
for stream in listener.incoming() {
if let Err(err) = stream {
eprintln!("error: {}", err);
continue;
}
let stream = stream.unwrap();
let mut reader = BufReader::new(stream);
let mut command_line = String::new();
loop {
if let Err(err) = reader.read_line(&mut command_line) {
eprintln!("error reading stream: {}", err);
break;
}
match Command::from_irc_string(&command_line) {
Ok(command) => {
// TODO: run command...
},
Err(err) => {
eprintln!("error parsing command: {}", err)
}
}
// Reset the buffer, avoids a new allocation
command_line.clear();
}
}
}
With these few lines of code, we can bind a listener to a socket, accept incoming connections and continuously parse received messages into IRC commands. I’d say that’s quite an achievement, so let’s pat ourselves on the back for a moment. {% gist %} Ok, enough celebrating. Let’s get back to business.
The fact of the matter right now is that our little server cannot do anything else other than continuously read the TCP stream. This is because we’re transferring ownership of the socket handle to the BufReader, so we cannot write to it so long as the reader holds it, that is to say, for the entirety of the connection. Fortunately, it turns out that this is really a non-issue because a TcpStream is nothing but a reference to a file descriptor, and the OS supports cloning any such file descriptor via the dup() and dup2() syscalls. Rust takes advantage of this fact by providing the try_clone method on TcpStream, which if successful gives us another owned handle to the same socket, that we can then pass to a BufWriter in order to respond to our client.
let stream = stream.unwrap();
let mut writer = BufWriter::new(stream.try_clone().unwrap());
let mut reader = BufReader::new(stream);
Ok, that was easy. Let’s now interact with our client by handling NICK messages. According to the IRC specification, the server may respond to a NICK
match Command::from_irc_string(&command_line) {
Ok(command) => {
match command {
Command::Nick(args) => {
let new_nickname = args.nickname;
let _ = writer.write_all(b"NICK ");
let _ = writer.write_all(new_nickname.as_bytes());
let _ = writer.write_all(b"\r\n");
let _ = writer.flush();
},
}
},
Err(err) => {
eprintln!("error parsing command: {}", err)
}
}
We’ve done it! We’re able to accept incoming requests, process them and write responses back to our clients. We just need to implement parsers and handlers for each command in the IRC spec and we’ll have a functioning server in no time, right? {% gist %} If it was really that simple, it would’t be worth writing a whole three-part series about it. In fact, while it is true that we can send messages back and forth with a client easily, with the way things are right now, because upon accepting a connection we enter in an infinite loop of stream I/O, we won’t be able to accept any additional connections until we break out of it. And since we can only break out of that loop when the client disconnects, our application won’t ever be able to handle more than one user at a time. And that is really not the best outlook for a chat application in my estimation, so we have to be smarter about how we handle connections.
Enter Multithreading
The way out of this conundrum is spawning additional threads and have them take care of interacting with the client. When I was learning about multithreading, I was stunned at the amount of confusing explanations, unclear definitions and misconceptions that you come across when you look up “What is a thread?” on Google or YouTube. While I’m a firm believer that simplifications are key for getting the point across when teaching, I also think that drawing a couple of squiggly lines on top of a rectangle, which seems to be a standard occurrence when explaining threads, is a rather poor way of explaining what threads are and what they can and cannot do. I’m going to explain multithreading briefly for the readers that may have heard of the term and may even have had to use multithreading APIs in languages such as Python and Node.js, but haven’t quite wrapped their head around what they are at their core (which was most definitely also my position before dealing with them in a low-level language like Rust). If you are already familiar with multithreading, feel free to skip ahead.
One of the main responsibilities of an operating system (OS) is to manage and allocate physical resources (such as RAM, CPU, etc.) among processes. When a new process is started on a machine, the OS allocates memory for it, which is divided into the text section, data section, stack, and heap. While the text section of a process contains the actual instructions that are going to be executed by the CPU to run the process, the order in which they are executed need not be sequential, which is already pretty evident by the presence of control flow structures like branches and loops. It is also not true that there can only be one such order in execution at any given time. In fact, starting from the same set of instructions, we could order them in multiple ways and run them concurrently (that’s to say, one along the others). A thread is essentially one such order of instruction executions, which also comes with its own stack memory. While there’s always at least one thread running per process, we can spawn others as we please, and these threads will share the underlying data, text and heap memory with the rest of the process.
The advantage of having multiple threads running in a process, is that an OS will be able to schedule them independently, so that if a thread is blocked (e.g., waiting on I/O like reading from a TCP socket), another thread can continue executing when the OS schedules it. We are going to make use of this fact to allow our server to process additional requests while we’re reading from an already connected stream.
While it is true that threads run somewhat independently, we can leverage the heap memory they all share to synchronize their states and have them communicate with each other. We are going to need this later on to allow two threads running concurrently to modify and access a shared state (in our case, a map from users to TCP handles). We must be careful though, because having separate threads rely on the same pieces of memory introduces the risk of data races, where two or more separate threads both want to access (with at least one thread wanting to modify) a shared resource at the same time. It goes without saying that the state of the shared resource in such an instance is highly non-deterministic, as it depends on how the OS has scheduled the threads to run, so we have to (or at least, we should) adopt some measures to prevent these situations from happening. As we’ll see, in Rust, these concepts are reflected in the type system, which allows the language to assess the memory-safety of a multithreaded application at compile time.
Handling multiple connections
We’re now ready to turn our single-threaded unicorn into a multi-threaded minotaur. All we need to do is spawn a new thread every time we get a new connection. The way we do that in Rust is by invoking the aptly named std::thread::spawn function and pass it a closure with the code we want our thread to run.
for stream in listener.incoming() {
if let Err(err) = stream {
eprintln!("error: {}", err);
continue;
}
let handle = thread::spawn(|| {
let stream = stream.unwrap();
let mut writer = BufWriter::new(stream.try_clone().unwrap());
let mut reader = BufReader::new(stream);
let mut command_line = String::new();
loop {
if let Err(err) = reader.read_line(&mut command_line) {
eprintln!("error reading stream: {}", err);
break;
}
match Command::from_irc_string(&command_line) {
Ok(command) => match command {
Command::Nick(args) => {
let new_nickname = args.nickname;
let _ = writer.write_all(b"NICK ");
let _ = writer.write_all(new_nickname.as_bytes());
let _ = writer.write_all(b"\r\n");
let _ = writer.flush();
}
},
Err(err) => {
eprintln!("error parsing command: {}", err)
}
}
command_line.clear();
}
});
}
You’ll notice that it’s essentially the same logic we had earlier, only that this time we are wrapping all the stream handling bits into a closure and handing it off to another thread.
With this little change, we can now respond to multiple clients requesting to change their nicknames at the same time, there’s just a little detail we forgot about. According to the IRC protocol, nicknames must be unique, i.e. no two users can share the same nickname at any given time.
At this point if you’re like me you’ll instinctively reach out for either a HashMap or a HashSet to keep track of the taken nicknames, but recall what we said about data races. What if two clients connected at the same time and wanted to set the same nickname? The threads handling their connections would both initially see an empty HashSet and hence would be entitled to think the chosen nickname is unique. They would both write the nickname to the hash set and respond positively to the client. And it would be much worse if we wanted to associate say, a TCP handle, to the a user’s nickname. It would mean that whatever thread the OS has scheduled to run last would overwrite the entry in the hash table for that username.
In other languages we would nonetheless be allowed to hold references to a shared hash map among multiple threads, let’s see how that would look like in Rust. We first create a “global” variable in the main thread and wrap it with a RefCell to allow multiple mutable borrows (potentially one for each thread).
let global_nicknames = RefCell::new(HashSet::new());
We are not using unsafe so we must explicitly handle the case where the global hash set is already being borrowed by another thread. Maybe we could wait in a loop until the variable becomes available again.
// NOTE: in connection handler thread
Command::Nick(args) => {
let mut nicknames = global_nicknames.try_borrow_mut();
while let Err(err) = nicknames {
// NOTE: this is not looking good already
nicknames = global_nicknames.try_borrow_mut();
}
let mut nicknames = nicknames.unwrap();
let new_nickname = args.nickname;
let nickname_is_taken = nicknames.contains(&new_nickname);
if nickname_is_taken {
// TODO: respond with an error
continue;
}
let _ = writer.write_all(b"NICK ");
let _ = writer.write_all(new_nickname.as_bytes());
let _ = writer.write_all(b"\r\n");
let _ = writer.flush();
nicknames.insert(new_nickname);
}
Although it seems like this program should at least work in principle, Rust won’t let us compile it, and will instead give us this error message:
`std::cell::RefCell<std::collections::HashSet<std::string::String>>`
cannot be shared between threads safely
the trait `std::marker::Sync` is not implemented for
`std::cell::RefCell<std::collections::HashSet<std::string::String>>`,
which is required by `{closure@src/main.rs:27:23: 27:25}: std::marker::Send`
if you want to do aliasing and mutation between multiple threads, use
`std::sync::RwLock` instead
required for
`&std::cell::RefCell<std::collections::HashSet<std::string::String>>`
to implement `std::marker::Send`
Alright, let’s try to decipher it. It’s telling us in the first line that a RefCell cannot be shared safely between threads. Let’s imagine why that would be the case. RefCell is a container for a variable that enforces Rust’s ownership rules at runtime rather than at compile time. The problem with RefCell is that it accomplishes this without any external help from the operating system. The logic checking whether it’s allowed to borrow global_nicknames is entirely within our program, and furthermore it relies on being run atomically (which in this case implies, on a single thread). That is to say, there could be a possibility of the OS deciding it’s time to switch execution from one thread to another in the worst time possible, i.e. when the thread is in the middle of determining whether it can borrow the variable or not, and this would of course open the possibility for a data race. Fortunately, the OS naturally implements some synchronization primitives that are guaranteed to run atomically, and Rust takes advantage of them by providing us wrappers like RwLock, which is also what the compiler is suggesting us to use instead of RefCell. RwLock allows us to either obtain a shared immutable reference or to exclusively obtain a mutable reference to an underlying variable. Furthermore, if a thread cannot acquire a lock right away, it will wait until it becomes available, (almost) just like in our implementation.
Command::Nick(args) => {
let new_nickname = args.nickname;
let nickname_is_taken = global_nicknames
.read().unwrap().contains(&new_nickname);
if nickname_is_taken {
// TODO: respond with an error
continue;
}
let _ = writer.write_all(b"NICK ");
let _ = writer.write_all(new_nickname.as_bytes());
let _ = writer.write_all(b"\r\n");
let _ = writer.flush();
global_nicknames.write().unwrap().insert(new_nickname);
}
We’re almost there, if we replace RefCell with RwLock we stil get an error when spawning the handler thread:
1. closure may outlive the current function,
but it borrows `global_nicknames`, which is owned by the current function
may outlive borrowed value `global_nicknames` [E0373]
2. function requires argument type to outlive `'static` [E0373]
3. to force the closure to take ownership of `global_nicknames`
(and any other referenced variables), use the `move` keyword: `move `
This error is easier to interpret. It seems that although we defined the global_nicknames variable in the body of the main function of the main thread, the compiler is unable to detect that it will outlive the handler threads spawned with each connection. Fortunately, it is also suggesting us two ways in which we could solve the problem:
- Force global_nicknames to be ‘static, which can be achieved somewhat sloppily by wrapping it in Box::leak(Box::new)
// NOTE: this now compiles
let global_nicknames = Box::leak(Box::new(RwLock::new(HashSet::new())));
- Transfer ownership of global_nicknames to the closure. Of course if we just used the move keyword on the closure the way it is now we would consume the hash map and make it unusable for the other threads. So what is usually done in this case is first wrapping the variable in an Arc smart pointer, and then cloning it before transferring ownership to the closure.
let global_nicknames = Arc::new(RwLock::new(HashSet::new()));
// ...
for stream in listener.incoming() {
// handle stream.is_err() ...
let global_nicknames = global_nicknames.clone();
thread::spawn(move || {
// rest of handler code ...
The Arc (Atomic Reference Count) smart pointer acts similarly to the well-known Rc pointer, with the key difference that updates to its reference count are performed atomically (and they need to be when working with multiple threads for the same reasons we stated above when talking about RefCell). When dealing with concurrency in Rust, it’s very common to see them wrapping either an RwLock like we did, or more commonly, a Mutex.
NOTE: The real core issue here is that thread::spawn requires all the references inside of its closure to outlive ‘static, which is not really necessary in our case since we are waiting on the thread to exit via the call to handle.join() in the main thread. Starting from Rust 1.63, the standard library allows us to create a scope for our worker threads to run in, which relaxes the lifetime requirements for references passed to them. Here’s what that would look like:
let global_streams = RwLock::new(HashMap::<String, TcpStream>::new());
let listener = TcpListener::bind("127.0.0.1:6667").unwrap();
std::thread::scope(|s| {
for stream in listener.incoming() {
s.spawn(|| {
let stream = stream.unwrap();
// rest of the handler
This also works perfectly well. However, we’re gonna be following the Arc route as, in addition to being the most common solution to this problem, it also better segues into async tasks (which we’ll see in Part 3).
We now have a solid foundation we can build upon to implement the remaining features of our application. Let’s move onto something that was long overdue, and which is actually the main purpose of our application: relaying messages.
Sending Messages
It’s finally time to put the ‘*Chat’ *in ‘Internet Relay Chat’.
If we take a look at the IRC protocol specification, we find that to send messages to another client or channel, a user must invoke the PRIVMSG command with two arguments:
-
The recipient(s) of the message, specified as a series of nicknames or channel names separated by commas
-
The content of the message
Here’s an example, if a client connected with the nickname *alice *wants to send a message to another client with nickname *bob, *she will send the following command to our IRC server:
PRIVMSG bob :Hello Bob!
It is then our job to relay this message to bob, specifying that it came from alice by adding the appropriate header to the message (recall that a message header specifies the original sender):
:alice PRIVMSG bob :Hello Bob!
Let’s get the easy things out of the way first, assuming for simplicity that only one message recipient can be specified, we can define the PrivMsg variant on the Command enum and the PrivMsgArgs structs in much of the same way as we did for the NICK command.
#[derive(FromIRCString)]
pub struct PrivMsgArgs {
pub target: String,
pub text: String,
}
#[derive(FromIRCString)]
pub enum Command {
#[command_name = "PRIVMSG"]
PrivMsg(PrivMsgArgs),
#[command_name = "NICK"]
Nick(NickArgs),
// other commands...
}
Now for our stream handler. We can keep our TCP handles within reach easily if we turn the global_nicknames hash set into a hash map having strings (nicknames) as its keys and TcpStreams as its values. We should also modify the NICK command handling code to once again clone the TCP handle to the current user and store it under its nickname for later use.
When handling a PRIVMSG command, we can then retrieve the appropriate TCP stream and write the message to it.
Here’s our final server code, you will notice that some variables have been renamed for the sake of clarity:
fn main() {
let global_streams =
Arc::new(RwLock::new(HashMap::<String, TcpStream>::new()));
let listener = TcpListener::bind("127.0.0.1:6667").unwrap();
for stream in listener.incoming() {
let global_streams = global_streams.clone();
thread::spawn(move || {
let stream = stream.unwrap();
let mut writer = BufWriter::new(stream.try_clone().unwrap());
let mut reader = BufReader::new(stream.try_clone().unwrap());
let mut command_line = String::new();
let mut current_nickname = String::new();
loop {
if let Err(err) = reader.read_line(&mut command_line) {
eprintln!("error reading stream: {}", err);
break;
}
match Command::from_irc_string(&command_line) {
Ok(command) => match command {
Command::Nick(args) => {
let new_nickname = args.nickname;
let nickname_is_taken = global_streams
.read()
.unwrap()
.get(&new_nickname)
.is_some();
if nickname_is_taken {
// TODO: respond with an error
continue;
}
let _ = writer.write_all(command_line.as_bytes());
let _ = writer.flush();
let mut nicknames = global_streams.write().unwrap();
if let Some(handle) = nicknames.remove(¤t_nickname) {
nicknames.insert(new_nickname.clone(), handle);
} else {
nicknames.insert(
new_nickname.clone(),
stream.try_clone().unwrap()
);
}
current_nickname = new_nickname;
}
Command::PrivMsg(args) => {
// get a handle to recipient's tcp socket
let mut streams = global_streams.write().unwrap();
let recipient_stream = streams.get_mut(&args.target);
if recipient_stream.is_none() {
// TODO: respond with error: no such nickname
continue;
}
// write the message with the correct header
let mut writer = BufWriter::new(recipient_stream.unwrap());
let _ = writer.write_all(b":");
let _ = writer.write_all(current_nickname.as_bytes());
let _ = writer.write_all(b" ");
let _ = writer.write_all(command_line.as_bytes());
let _ = writer.flush();
}
},
Err(err) => {
eprintln!("error parsing command: {}", err)
}
}
command_line.clear();
}
});
}
}
We can now try using something like telnet to have two clients connect to our server, set nicknames and send messages to each other.
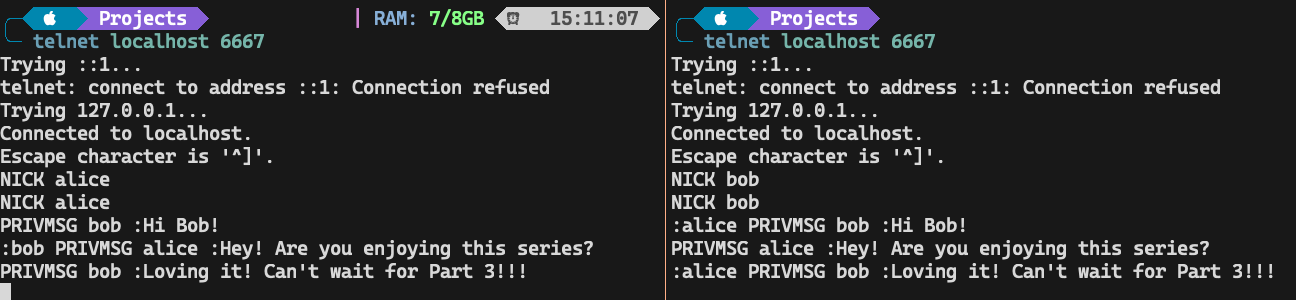
It’s been a long journey to get here, but we’re not done yet. There are at least two major flaws with our current implementation:
-
We’re both keeping a dedicated BufWriter for the currently connected stream, and creating a new one whenever needed (e.g. for sending a message to another user). This means that we could potentially have two writers write to the same stream at the same time. For small messages this shouldn’t pose much of an issue, but it’s possible that larger ones may get interleaved in the stream, corrupting them.
-
More importantly, we’re locking the shared state too often. With our current setup it’s difficult to come up with a situation in which a handler would not need an exclusive lock on the global_streams table. Hence, in the ever more likely case that a handler needs to wait for the lock to be released, the thread would be unable to process additional messages sent by the client, which need not be the case for IRC, since it’s an asynchronous protocol.
To fix these issues, we will take a look at some patterns we can employ to decouple the business logic of our application from access to the shared state. In particular, we’ll implement a simplified actor-pattern-style dispatcher thread that will take care of delivering messages to the clients on behalf of the command handlers. In addition to this, we’ll take a brief look at the tokio async runtime, and how we can employ it to make our server even more resource-efficient.
This article was quite long and involved so I’m honored you found it sufferable enough to have made it up to here. I hope you are enjoying this series and can’t wait to see you in Part 3.
Alla prossima! (‘till next time!)